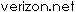0800- F4 34 12 PEA $1234
0800- A9 12 LDA /$1234
0802- 48 PHA
0803- A9 34 LDA #$1234
0805- 48 PHA


| Volume 6 -- Issue 11 | August 1986 |
In This Issue...
About five minutes ago, about two hours before this issue goes to the printer, our UPS driver delivered one review copy of Programming the 65816, by David Eyes and Ron Lichty. IT'S HERE! And it looks excellent. I have time and space for only a few words here; we expect to have a complete review of this book and Fischer's next month.
Eyes and Lichty have given use over 600 pages of introduction, architecture, tutorial, application, and reference information, including a 60-page chapter listing and describing in detail the source code for a rudimentary 65816 Tracer/Debugger. This book has complete information on ALL the 65x family processors, from the original 6502 up through these latest 16-bit versions.
We expect delivery of our inventory within the next week or two and we'll start shipping your copies as soon as we get them. Remember, our price is $21 + shipping.
| Minor Correction to Bob's New QUIT Code | Erv Edge |
Bob's new QUIT code for ProDOS is nice! There is one minor error at line 3390, which causes an extra character to be printed. Change "BNE .1" to "BPL .1" and it will work better. The extra character was only noticeable when the filename was 15 characters long, or had been RENAMEd to a shorter name than it previously had, because filenames are normally filled out with null characters.
You can also save one byte by changing line 4290 from "JMP MSG" to "BNE MSG". The BNE will always branch in this case, and is one byte shorter than the JMP.
| Fast Integer Square Roots | Bob Sander-Cederlof |
In the July 1986 issue of Dr. Dobb's Journal, Robert Pirko gave an algorithm and a program to calculate the square root of a 16-bit integer. (Letter, pages 10-12; program, pages 60-66.) His program was written in 8088 assembly language for the IBM PC. I decided to try writing the same algorithm in 6502 code.
As with most square root algorithms, Pirko's depends on the so-called Newton-Raphson iteration. In simple algebra, this means that a "pretty good" approximation to the square root of N can be made "much better" by the formula:
1 N
much better = ---( pretty good + ----------- )
2 pretty good
How many times you have to use the formula depends on how close your first guess is, and how much precision you need. By the definition of "integer square root", we are looking for the largest 8-bit integer whose square is less than or equal to the 16-bit argument N. Therefore, we need only 8-bit precision.
The formula refines the answer rapidly, roughly doubling the number of precise bits each time. So if we start with a close enough initial guess, once through the formula might be plenty.
What Pirko did was experiment to find a set of rules to get a "good enough" initial guess. Once through Newton-Raphson refined the guess to 8-bit precision, except that the truncation errors of integer arithmetic resulted in some roots being too large by 1. By squaring the calculated root and comparing the original number, Pirko could decrement those which needed it.
Pirko's program was pretty fast. He tested speed by taking the square roots of all integers from 0 to 65535, with the average time being 91 microseconds on his IBM PC (he didn't say which version, or what clock frequency). Any time I see a timed program like this, my benchmarking blood begins to bubble. However, the Apple is not as fast this time, because of the need for a division and a multiplication. The 8088 has opcodes for multiply and divide, while the 6502 does not.
Here are Pirko's rules for obtaining an initial guess:
Argument
Range Root or Initial Guess
---------------------------------
0000-0001 root = N
0002-00FF guess = N/16 + 3
0100-0FFF guess = Nhigh*4 + 13
1000-7FFF guess = Nhigh + 50
8000-D7FF guess = Nhigh + 40
D800-FEFF guess = 255
FF00-FFFF root = 255
After playing with various versions of the program, I settled on a slightly different set of rules. The average time was reduced a little by changing the third and fourth ranges:
0100-08FF guess = Nhigh*4 + 13
0900-7FFF guess = Nhigh + 50
It is not difficult to separate out the seven cases and calculate the initial guess. Lines 1130-1460 in the program below do all that work. Lines 1480-1530 perform the Newton-Raphson formula once. Lines 1540-1630 decrement the root if its square exceeds the original argument.
Since the 6502 does not have any multiply or divide opcodes, I coded these two operations as subroutines. My division subroutine divides the 16-bit value in ARGHI,ARGLO by the 8-bit value in GUESS, leaving the answer in QUOT and REM. My multiplication subroutine multiplies the 8-bit value in the A-register by the 8-bit value in ROOT to get a 16-bit product in PROD.
The program named MT (lines 3390-3850) does a complete test of the square root subroutine. MT calls on SQR for each possible argument from 0 through 65535 ($FFFF), then tests the value of ROOT by squaring it. If the square is larger than the argument, there was an error. If not, I increment the root and square it again. If this square is not larger than the argument, there was an error. If either type of error occurs, I display the argument and the root.
Once I was sure SQR was producing correct answers, I wrote a timing routine (lines 2110-2430) which runs through all values 0-65535 ten times. By changing line 1190 to "1190 SQR RTS" I timed the overhead of the 655360 calls (13.2 seconds). When I changed line 1190 back, the additional time was 273.3 seconds. This is an average of 417 microseconds per root, over 4 times slower than the IBM program.
I wanted to see what the 6502 could do IF it had multiply and divide opcodes in hardware. Assuming each would take no more than 12 cycles, I changed lines 1740 and 1940 to RTS's. The resulting time averaged 74.3 microseconds per root. If only we had DIV and MUL, we could easily beat the PC in this benchmark.
We can come a little closer by playing a dirty trick. Since we know that the test program runs through all the arguments in sequence, we know that the squaring operation will usually be doing the same number over and over. For example, the root $FE comes out of the Newton-Raphson formula over 500 times! By giving the MUL routine a memory, we can save the root squared last time. Lines 1950-1970 are all we need to add. Simply remove the asterisks and re-assemble. With this trick, the average root took only 248 microseconds. We can also save about 24 microseconds per root by putting the MUL and DIV subroutines "in-line", eliminating the JSR and RTS (with the dirty trick, in-line code only saves an additional 12 microseconds).
Some time ago, Technical Education Research Centers (TERC) published information on the Hitachi 6203 multiply/divide chip and how to interface it to the Apple. We mentioned this in AAL a few years back. That chip allows you to code the division in my program to run in 33 cycles, and the squaring in 30 cycles. The result would still be a little slower than the PC. By the way, all I know about the 6203 I got from TERC's newsletter. I have never been able to get any information whatsoever out of Hitachi about it, and I have never actually seen the chip. I sure would like to! (If you are interested in TERC, try calling Bob Tinker or his associates at (617) 547-0430, or write to TERC, 1696 Massachusetts Avenue, Cambridge, MA 02138.)
I am not finished yet. I spent another half day investigating a different technique for getting the integer square root. This is a binary adaptation of the mysterious method we learned and forgot in high school. Can you remember how we did it? I know at least a few of you can, because you are in high school right now. And others, because you are high school teachers. Anyway, it is too difficult to explain in these few lines. The same algorithm in binary is pretty straightforward. I present it in lines 2490-3020, without much comment. It works, but it takes an average of about 880 microseconds per root. The test routine in lines 3040-3350 takes the square root of evey value from 0-65535 using both SQR and NEWSQR, and compares the results. If they are different, it prints the data.
It is now nearly a month since I wrote all the preceding paragraphs in this article. Today the latest Dr. Dobbs Journal arrived, and a pair of letters referred to some old articles about integer square roots. I looked them up, and learned an easier way to apply the "high school" method. The resulting 6502 program won't fit in this issue, but is included on the Monthly and Quarterly Disks. This version takes an average of 737 cycles per root. It looks like a 65802 native mode version would be significantly faster.
Naturally, I expect at least one of you to come up with a significantly better and faster program than any of mine.
1000 *SAVE S.INTEGER.SQRT 1010 .LIST CON 1020 *-------------------------------- 1030 ARGLO .EQ 0 1040 ARGHI .EQ 1 1050 GUESS .EQ 2 1060 QUOT .EQ 3 1070 REM .EQ 4 1080 ROOT .EQ 5 1090 PROD .EQ 6,7 1100 TRIPS .EQ 8 1110 PREVIOUS.ROOT .EQ 9 1120 BITHI .EQ 10 1130 BITLO .EQ 11 1140 SUBHI .EQ 12 1150 SUBLO .EQ 13 1160 WORKHI .EQ 14 1170 WORKLO .EQ 15 1180 *-------------------------------- 1190 SQR 1200 LDA ARGHI 1210 BMI .1 32768 OR MORE 1220 BNE .2 256...32767 1230 LDA ARGLO 1240 LSR 1250 BEQ .8 ...ARG= 0 OR 1 1260 LSR 1270 LSR 1280 LSR 1290 ADC #3 (2...5 IS OKAY HERE 1300 BNE .4 ...ALWAYS 1310 *---32768...65535---------------- 1320 .1 CMP #255 1330 BEQ .7 (A)=255=ROOT 1340 ADC #40 (35...44 OKAY) 1350 BCC .4 1360 LDA #255 1370 BNE .4 ...ALWAYS 1380 *---256...32767------------------ 1390 .2 CMP #$09 1400 BCS .3 $0900...$7FFF 1410 ASL $0100...$08FF 1420 ASL 1430 ADC #13 1440 BNE .4 ...ALWAYS 1450 *---$0900...$7FFF---------------- 1460 .3 ADC #49 ADDS 50 (50...61 OKAY) 1470 *---DO NEWTON ONCE--------------- 1480 .4 STA GUESS 1490 JSR DIV 1500 CLC 1510 LDA QUOT 1520 ADC GUESS 1530 ROR 1540 *---SQUARE THE RESULT------------ 1550 STA ROOT 1560 JSR MUL 1570 *---DECREMENT ROOT IF TOO BIG---- 1580 LDA ARGLO 1590 CMP PROD 1600 LDA ARGHI 1610 SBC PROD+1 1620 LDA ROOT 1630 SBC #0 DECREMENT IF TOO BIG 1640 *-------------------------------- 1650 .7 STA ROOT 1660 RTS 1670 *-------------------------------- 1680 .8 ROL RESTORE 0 OR 1 1690 BCC .7 ...ALWAYS 1700 *-------------------------------- 1710 * DIVIDE (ARGLO,ARGHI) BY (GUESS) 1720 * LEAVE ANSWER IN QUOT,REM 1730 *-------------------------------- 1740 DIV 1750 LDY #8 1760 LDA ARGLO 1770 STA QUOT 1780 LDA ARGHI 1790 .1 ASL QUOT 1800 ROL 1810 BCS .15 1820 CMP GUESS 1830 BCC .2 1840 .15 SBC GUESS 1850 INC QUOT 1860 .2 DEY 1870 BNE .1 1880 STA REM 1890 RTS 1900 *-------------------------------- 1910 * MULTIPLY (ROOT) BY (A-REGISTER) 1920 * PUT RESULT IN PROD,PROD+1 1930 *-------------------------------- 1940 MUL 1950 *** CMP PREVIOUS.ROOT "DIRTY TRICK" 1960 *** BEQ .7 ditto 1970 *** STA PREVIOUS.ROOT ditto 1980 STA GUESS 1990 LDA #0 2000 LDY #8 2010 .5 LSR GUESS 2020 BCC .6 2030 CLC 2040 ADC ROOT 2050 .6 ROR 2060 ROR PROD 2070 DEY 2080 BNE .5 2090 STA PROD+1 SAVE HI-BYTE OF SQUARE 2100 .7 RTS 2110 *-------------------------------- 2120 T 2130 LDA #10 2140 STA TRIPS 2150 LDA #0 2160 STA ARGHI 2170 STA ARGLO 2180 STA PREVIOUS.ROOT 2190 *-------------------------------- 2200 .1 JSR SQR 2210 .DO 0 2220 LDA ARGHI 2230 JSR $FDDA 2240 LDA ARGLO 2250 JSR PRB 2260 LDA ROOT 2270 JSR PRB 2280 LDA PROD+1 2290 JSR $FDDA 2300 LDA PROD 2310 JSR PRB 2320 JSR $FD8E 2330 .FIN 2340 *-------------------------------- 2350 INC ARGLO 2360 BNE .1 2370 INC $7F7 2380 INC ARGHI 2390 BNE .1 2400 INC $7F5 2410 DEC TRIPS 2420 BNE .1 2430 RTS 2440 *-------------------------------- 2450 PRB JSR $FDDA 2460 LDA #" " 2470 JMP $FDED 2480 *-------------------------------- 2490 NEWSQR 2500 LDY #8 Loop 8 times for an 8-bit root 2510 LDA ARGHI 2520 STA WORKHI Save working copy of argument 2530 LDA ARGLO 2540 STA WORKLO 2550 LDA #0 SUB0 = $4000 2560 STA SUBLO BIT0 = $4000 2570 STA BITHI 2580 LDA #$40 2590 STA SUBHI 2600 STA BITHI 2610 *-------------------------------- 2620 .1 SEC Trial subtraction 2630 LDA WORKLO 2640 SBC SUBLO 2650 TAX Save lo-byte of difference 2660 LDA WORKHI 2670 SBC SUBHI 2680 BCC .2 ...WORKi < SUBi 2690 STA WORKHI Save new value for WORK 2700 STX WORKLO 2710 .2 PHP Save carry status (next ROOT bit) 2720 ROL ROOT ROOT = ROOT*2 + CARRY 2730 LDA SUBHI SUB = (SUB .EOR. BIT)/2 2740 EOR BITHI 2750 LSR 2760 STA SUBHI 2770 LDA SUBLO 2780 EOR BITLO 2790 ROR 2800 STA SUBLO 2810 PLP 2820 BCC .3 ...WORK was less than SUB 2830 LDA SUBHI SUB = SUB .EOR. BIT 2840 EOR BITHI 2850 STA SUBHI 2860 LDA SUBLO 2870 EOR BITLO 2880 STA SUBLO 2890 .3 LSR BITHI BIT = BIT/4 2900 ROR BITLO 2910 LSR BITHI 2920 ROR BITLO 2930 LDA SUBHI SUB = SUB .EOR. BIT 2940 EOR BITHI 2950 STA SUBHI 2960 LDA SUBLO 2970 EOR BITLO 2980 STA SUBLO 2990 *-------------------------------- 3000 DEY 3010 BNE .1 3020 RTS 3030 *-------------------------------- 3040 TT 3050 LDA #0 3060 STA ARGHI 3070 STA ARGLO 3080 STA PREVIOUS.ROOT 3090 *-------------------------------- 3100 .1 JSR NEWSQR 3110 LDA ROOT 3120 PHA 3130 JSR SQR 3140 PLA 3150 CMP ROOT 3160 BEQ .11 3170 PHA 3180 .DO 1 3190 LDA ARGHI 3200 JSR $FDDA 3210 LDA ARGLO 3220 JSR PRB 3230 LDA ROOT 3240 JSR PRB 3250 PLA 3260 JSR PRB 3270 JSR $FD8E 3280 .FIN 3290 *-------------------------------- 3300 .11 INC ARGLO 3310 BNE .1 3320 INC $7F7 3330 INC ARGHI 3340 BNE .1 3350 RTS 3360 *-------------------------------- 3370 * COMPLETE TEST OF ALL POSSIBLE ARGUMENTS 3380 *-------------------------------- 3390 MT 3400 LDA #0 3410 STA ARGLO 3420 LDA #$00 3430 STA ARGHI 3440 *-------------------------------- 3450 .1 JSR SQR 3460 LDA ROOT 3470 JSR MUL 3480 LDA ARGLO 3490 CMP PROD 3500 LDA ARGHI 3510 SBC PROD+1 3520 BCC .9 ROOT TOO LARGE 3530 INC ROOT 3540 BEQ .2 3550 LDA ROOT 3560 JSR MUL 3570 DEC ROOT 3580 LDA ARGLO 3590 CMP PROD 3600 LDA ARGHI 3610 SBC PROD+1 3620 BCS .9 ROOT TOO SMALL 3630 *-------------------------------- 3640 .2 INC ARGLO 3650 BNE .1 3660 INC ARGHI 3670 LDA ARGHI 3680 LSR 3690 LSR 3700 LSR 3710 LSR 3720 ORA #"0" 3730 STA $7F7 3740 LDA ARGHI 3750 BNE .1 3760 RTS 3770 *-------------------------------- 3780 .9 LDA ARGHI 3790 JSR $FDDA 3800 LDA ARGLO 3810 JSR PRB 3820 LDA ROOT 3830 JSR $FDDA 3840 JSR $FD8E 3850 JMP .2 3860 *-------------------------------- 3870 ERRHI .EQ 16 3880 ERRLO .EQ 17 3890 *-------------------------------- 3900 * METHOD DERIVED FROM 68000 CODE IN DDJ MAY 85 3910 * 6502 VERSION AVERAGES 737 CYCLES 3920 *-------------------------------- 3930 SQR3 LDA ARGHI Save working copy of argument 3940 STA WORKHI 3950 LDA ARGLO 3960 STA WORKLO 3970 LDA #0 3980 STA ROOT Start with ROOT = 0 3990 STA ERRHI and ERR = 0 4000 STA ERRLO 4010 *-------------------------------- 4020 LDY #8 8 pairs of bits in argument 4030 .1 ASL WORKLO Two bits out of WORK into ERR 4040 ROL WORKHI 4050 ROL ERRLO 4060 ROL ERRHI 4070 ASL WORKLO 4080 ROL WORKHI 4090 ROL ERRLO 4100 ROL ERRHI 4110 ASL ROOT ROOT = ROOT*2 4120 LDA ROOT BIT = ROOT*2 4130 ASL 4140 STA BITLO 4150 LDA #0 4160 ROL 4170 STA BITHI 4180 LDA ERRLO (CARRY IS CLEAR) 4190 SBC BITLO COMPUTE: ERR-BIT-1 4200 TAX SAVE LO DIFFERENCE 4210 LDA ERRHI 4220 SBC BITHI 4230 BCC .2 ERR < BIT 4240 STA ERRHI 4250 STX ERRLO 4260 INC ROOT ROOT = ROOT+1 4270 .2 DEY 4280 BNE .1 4290 RTS 4300 *-------------------------------- |
| Updated Memory-vs.-File Maps for ProDOS | Bob Sander-Cederlof |
I am not sure how it happened, but I seem to have botched up the table on page 20 of the November 1985 issue. As I now understand it, the relationship between the PRODOS file image (which loads at $2000) and the image of ProDOS after it is loaded is as follows (the lines marked with * are the changed lines):
2000-287E ProDOS Installer Code
287F-28FE zeroes
28FF-293C Installer for /RAM Driver
293D-29FF zeroes
2A00-2BFF Aux 200-3FF /RAM/ Driver
* 2C00-2C99 FF00.FF99 /RAM/ Driver
2C7F-2CFF zeroes
* 2D00-4DFF DE00-FEFF MLI Kernel
4E00-4EFF BF00-BFFF System Global Page
* zeroes D700-DDFF
4F00-4F7C D742-D7BE Thunderclock driver
4F80-4FFF FF80-FFFF Interrupt Code
* 5000-56FF D000-D6FF Device Drivers
5700-59FF Alt D100-D3FF QUIT Code
Looking at the same information from the viewpoint of the finished product, here is a map of ProDOS after it is loaded:
4E00-4EFF BF00-BFFF System Global Page
* 5000-56FF D000-D6FF Device Drivers
* zeroes D700-DDFF
4F00-4F7C D742-D7BE Thunderclock driver
* 2D00-4DFF DE00-FEFF MLI Kernel
* 2C00-2C99 FF00-FF99 /RAM/ Driver
4F80-4FFF FF80-FFFF Interrupt Code
5700-59FF Alt D100-D3FF QUIT Code
| DUMP Command for DOS 3.3 | Bill Morgan |
Back in March, 1984 Bob S-C wrote up a modification to the DOS VERIFY command processor to make that command do a hex dump of a file. This can be a very useful tool, giving us the ability to see exactly what's stored in any file of any type, so of course I wanted to include it in the DOS I've been building for the UniDisk 3.5. In his version Bob provided a 40-column hex-only display and invited the reader to expand it to 80 columns with ASCII as well. That's what I've done here, as well as adding pause and abort features. I didn't get as far as his suggestion to allow paging through the file either backwards or forwards, so there's still something left for you tinkerers.
As written here DUMP runs in 158 bytes of page 3. I got involved in making it better, rather than making it smaller, so it still won't fit inside of DOS yet. Maybe next time around.
There is a side effect of modifying VERIFY. Both SAVE and BSAVE call VERIFY after they're done, to make sure all went well. The first time I got this patch working and then SAVEd the file I got a nice dump all over the screen at the end of the SAVE. That's why I ended up having the DUMP command call a little routine that patches into the VERIFY code, calls it, and then de-patches itself. This means that if you RESET out of a DUMP, or if you get an I/O ERROR, the DUMP patch will still be in place and you'll probably want to disconnect it. You can do that either by doing a successful DUMP command, or by calling the disconnect routine directly ($329G or CALL 809).
So, on to the code. By the way, I use a couple of 65C02 opcodes in this program, but the equivalent 6502 instructions are shown {in curly brackets} in the comment field.
INSTALL points the command vector to my routine and changes the command name from VERIFY to DUMP. Normally when you change a DOS command name the new name must have the same number of letters as the old one, but since VERIFY is the last name in the list we can truncate it and fill the ending bytes with zeroes.
PATCH is called when we type the DUMP command. Here we patch into the VERIFY processor to call DUMP in place of the call to get the next sector of the file. It then calls VERIFY as usual and then puts it back. This way we can get the sector and display it when it's our command, but leave the normal VERIFY operation undisturbed so SAVE and BSAVE can function normally.
DUMP first does the GET.SECTOR call we patched in over, exiting when we hit the end of the file. The next step is to prepare the display so we print a blank line and display the relative sector number in the file. Note that this is not a disk track or sector number; this is the position in the track/sector list. We then set the Y-register to the beginning of the sector buffer and branch into the code to display one line.
The line display routines starting at line 1600 normally begin by printing four spaces to allow for the sector number printed on the first line. After that we print the offset into the sector from the Y-register and a separating dash. Notice that the PRINT.BYTE and PRINT.DASH routines also output a trailing space. Now it's time to get the next 16 bytes from the file, stash them in a buffer for later ASCII printing, and display them in hexadecimal. (The stash buffer is inside the secondary filename buffer, which is used only during a RENAME command.) The odd code in lines 1730-1780 has the effect of printing an extra space after every four bytes, to separate the display into columns and improve readability.
The last steps in displaying a line are to recover the 16 bytes from the buffer, make them printable and replace any control characters with underlines, and send them on out. (Most programs seem to replace control characters with periods, but I chose the underline so I could more easily see the real periods in the file. Underlines are much rarer in typical text.) After that we check the keyboard for a pause or abort and check to see if we've finished the sector yet. If necessary we branch back and do the next line.
PAUSE is lifted straight from the SHOW command article in AAL July, 1982. As a matter of fact, since I always install SHOW I just call PAUSE at $AE8E rather than including it in DUMP. This is a very useful routine to keep around.
1000 *SAVE S.DUMP
1010 .OP 65C02
1020 *--------------------------------
1030 *
1040 * Patch DOS to change
1050 * VERIFY into DUMP
1060 *
1070 *--------------------------------
1080 POINTER .EQ $42
1090 VECTOR .EQ $9D54
1100 VERIFY .EQ $A27D
1110 VFY.NAME .EQ $A902
1120 BUFFER .EQ $AAA0
1130 READ.CALL .EQ $AD1C
1140 GET.SECTOR .EQ $B0B6
1150 SECTOR .EQ $B5E4
1160 KEYBOARD .EQ $C000
1170 STROBE .EQ $C010
1180 MON.PRNTAX .EQ $F941
1190 MON.PRBL2 .EQ $F94A
1200 MON.CROUT .EQ $FD8E
1210 MON.PRBYTE .EQ $FDDA
1220 MON.COUT .EQ $FDED
1230 *--------------------------------
1240 .OR $300
1250 * .TF B.DUMP
1260 *--------------------------------
1270 INSTALL LDA /PATCH-1 point DOS vector table
1280 STA VECTOR+1 to my patch
1290 LDA #PATCH-1
1300 STA VECTOR
1310 LDX #5
1320 .1 LDA COMMAND,X change VERIFY command
1330 STA VFY.NAME,X name to DUMP
1340 DEX
1350 BPL .1
1360 RTS
1370 COMMAND .AT /DUMP/
1380 .HS 0000
1390 *--------------------------------
1400 PATCH LDA #DUMP hook into VERIFY command
1410 STA READ.CALL
1420 LDA /DUMP
1430 STA READ.CALL+1
1440 JSR VERIFY call it
1450 LDA #GET.SECTOR restore normal VERIFY
1460 STA READ.CALL
1470 LDA /GET.SECTOR
1480 STA READ.CALL+1
1490 RTS
1500 *--------------------------------
1510 DUMP JSR GET.SECTOR read next sector
1520 BCS .7 end of file
1530 JSR MON.CROUT start sector with <CR>
1540 LDA SECTOR+1
1550 LDX SECTOR
1560 JSR MON.PRNTAX display sector position
1570 LDY #0 start at beginning of sector
1580 BEQ .2 ...always
1590
1600 .1 LDX #4 print 4 blanks
1610 JSR MON.PRBL2 so columns look neater
1620 .2 TYA
1630 JSR PRINT.BYTE print byte count
1640 JSR PRINT.DASH separator
1650 LDX #15 16 bytes per line
1660 .3 LDA (POINTER),Y get byte from file
1670 STA BUFFER,X stash it
1680 JSR PRINT.BYTE print as hex value
1690 INY next byte
1700 DEX
1710 BMI .4 done with this line?
1720
1730 TXA check X
1740 INC {EOR #%00000011}
1750 AND #%00000011
1760 BNE .3 every fourth byte
1770 JSR PRINT.SPACE skip a space
1780 BRA .3 {JMP .3}
1790
1800 .4 JSR PRINT.DASH separator
1810 LDX #15 16 bytes
1820 .5 LDA BUFFER,X get stashed value
1830 ORA #%10000000 hi-bit on
1840 CMP #" "
1850 BCS .6 filter out controls
1860 LDA #"_" substitute "_"
1870 .6 JSR MON.COUT print as ASCII
1880 DEX
1890 BPL .5 back for more
1900
1910 JSR MON.CROUT next line
1920 JSR PAUSE check for pause or
1930 BEQ .7 abort
1940 CPY #0 done with sector?
1950 BNE .1
1960 CLC normal exit
1970 RTS
1980 .7 SEC EOF or abort exit
1990 RTS
2000 *--------------------------------
2010 PRINT.DASH
2020 LDA #"-"
2030 JSR MON.COUT
2040 BRA PRINT.SPACE {JMP PRINT.SPACE}
2050 PRINT.BYTE
2060 JSR MON.PRBYTE
2070 PRINT.SPACE
2080 LDA #" "
2090 JMP MON.COUT
2100 *--------------------------------
2110 * RETURN .EQ. IF ABORT
2120 * .NE. IF CONTINUE
2130 *--------------------------------
2140 PAUSE LDA KEYBOARD any key pressed?
2150 BPL .2 no, continue
2160 STA STROBE yes, clear strobe
2170 CMP #$8D abort?
2180 BEQ .2 yes, return .EQ. status
2190 .1 LDA KEYBOARD no, pause 'til keypress
2200 BPL .1 none pressed yet
2210 STA STROBE clear strobe
2220 CMP #$8D abort?
2230 .2 RTS .EQ. if abort
2240 .LIF
|
| Compatibility with the Laser-128 | Bob Sander-Cederlof |
We borrowed a Laser-128 (popular clone of the Apple //c) the other day. It had been rumored that our software would not run on it, in spite of Central Point Software's sanguine claims. Sure enough, the S-C Macro Assembler would not operate, under either DOS or ProDOS. They boot and load, but no more.
A little investigation revealed what we expected: our software uses at least a half-dozen entry points into the Apple monitor which are not supported in the Laser-128 monitor. Most of them have to do with our "$" command, which lets you perform monitor commands without leaving the S-C environment. These patches will disable the "$" command and repair the "MEM" command. The addresses shown are for our current release disks.
DOS 3.3 $1000 version 1AE6:4C B3 1B 20 40 F9 A9 AD 4C ED FD
124A:E9 1A (was 99 FD)
125D:E9 1A (was 99 FD)
DOS 3.3 $D000 version DAE6:4C B3 DB 20 40 F9 A9 AD 4C ED FD
D24A:39 DA (was 99 FD)
D25D:E9 DA (was 99 FD)
ProDOS version 8B45:4C 24 8C 20 40 F9 A9 AD 4C ED FD
8450:48 8B (was 99 FD)
8463:48 8B (was 99 FD)
Make a backup copy of the disk, and then boot the backup copy. When the assembler version you choose has loaded, type the letter X and the RETURN key. This should BRK out of the assembler into the Laser-128 monitor. Make the patches as shown above, and then type "3D0G" or control-RESET to get back into the assembler. It should be working correctly now. If you are fixing the DOS 3.3 version, you can now BSAVE the patched code on the file you originally loaded.
If you are fixing the ProDOS version, you now should BLOAD the type SYS file called SCASM.SYSTEM. The same patches you just made to the assembler should now be applied to the image of the SYS file, and then BSAVE the image on the disk:
:BLOAD SCASM.SYSTEM,TSYS,A$2000
:MNTR
*2D45:4C 24 8C 20 40 F9 A9 AD 4C ED FD
*2650:48 8B
*2663:48 8B
*3D0G
:BSAVE SCASM.SYSTEM,TSYS,A$2000,L17920
One incompatibility remains for which we never found the cause: the esc-L shorthand command, to turn a CATALOG line into a LOAD command, does not work in 80-column mode. It does work just fine in 40-column mode. If any of you try these patches and find other problems, we would like to hear about them.
One more item: we found the Laser-128 monitor incorrectly disassembles the PLX command as PHX.
| Convert Lo-Res Pictures to Double Hi-Res (with Info about Two Secret RGB Modes) |
David C. Johnson |
In the January '86 AAL, Bob presented a routine to convert lo-res to regular hi-res. He pointed out that "it is not possible to exactly reproduce the lo-res colors on the hi-res screen (unless I used //e or //c double hi-res)." Bob's routine used patterns to "come close to the same color." He also wrote that he didn't have a color monitor and didn't know how close he got. I have an RGB color monitor, and patterns result in most unsatisfactory conversion. This article offers three satisfactory conversion routines that, of course, use double hi-res.
Regular color double hi-res, which will work on a color TV, a composite color monitor, or an RGB monitor (mode 2 or 3), has a resolution of 140 by 192. Lo-res has a resolution of 40 by 48. Since 140 is not evenly divisible by 40, regular color double hi-res is not capable of displaying a satisfactory representation of a lo-res picture. You can reproduce all sixteen colors, but you can't get satisfactory resolution of 40 lo-res columns. An RGB monitor, driven by an AppleColor (or compatible) card, can display a PERFECT double hi-res version of a lo-res picture two different ways. Two of my routines perform these color conversions and work ONLY for RGB. Without RGB they look lousy. The third routine, included for completeness, performs a monochrome conversion and will work on an RGB monitor (mode 1) or a monochrome monitor.
I'm writing this article so I may present examples of how the RGB-only video modes work. The two color routines use modes that are not described in the AppleColor card manual. The AppleColor card comes with demo disks that show foreground/ background hi-res; a Video-7 demo disk I have shows "160 Mode". Except for these two simple demos and a collection of programs which I have written, I know of no programs, commercial or otherwise, using these modes. By the way, while I do have a //c, I don't have an RGB interface for it, so I don't know if Video-7's (or anyone else's) //c RGB Adapter supports these modes or is compatible with the AppleColor card. I would be interested in hearing from any of you on these subjects at: 41 Putnam Park Road, West Redding, CT 06896.
F/B hi-res works much like monochrome regular hi-res. Main memory bytes define the screen at seven pixels each (bit 7 is ignored - no half shifting), but instead of each 1 bit producing an "on" pixel and each 0 bit an "off" pixel, each 1 bit produces a "foreground" pixel and each 0 bit a "background" pixel. Auxiliary memory bytes define the F/B colors of the seven pixels at the same address in main memory. The high nybbles contain the foreground colors and the low nybbles the background colors. For example, aux $2000:12 and main $2000:55 would produce magenta, dark blue, magenta, dark blue, magenta, dark blue, and magenta beginning at the top left. In effect you get 280x192 resolution with sixteen colors! Of course, since F/B colors are defined for each group of seven pixels, not each pixel, you can only get two colors per seven pixels.
With "160 Mode", the "given" of using only seven bits of every byte for pixel information is gone. All eight bits of both the auxiliary and main memory pages are used. It seems (to me) to be more closely related to lo-res than hi-res, only "sideways" and with sixteen times the resolution. Low nybbles define the even columns and high nybbles the odd columns, while in lo-res the correspondence is between nybbles and rows. Auxiliary memory pairs precede main memory pairs. For example, aux $2000:21 and main $2000:43 would produce: magenta, dark blue, purple, and dark green beginning at the top left. Effective resolution is 160x192 with sixteen colors and no restrictions!
Both the RGB modes offer superior pictures compared to regular hi-res and (regular) double hi-res. They also offer other advantages important to programmers. We can manipulate F/B hi-res images pixel data separately from the color data. "160 Mode" images can be drawn in 80 different horizontal positions without any shifting, and the other 80 are only a 4 bit shift (or look up) away using whole bytes. Best of all, the bits that define a colored pixel don't ever fall in different bytes!
The three routines may be tested by entering at labels "a", "b" and "c". These are extensions the demo "T" in Bob's program. I have also kept his "PLOT" and "PAUSE.FOR.ANY.KEY" routines. I've rearranged Bob's code to handle some //e (and //c) stuff, the double hi-res video modes, etc. You should refer back to his article, and compare our code. One thing that I didn't carry forward from Bob's code is his stepping through the screen memory using Cartesian coordinates. My routines crank along sequentially. The video mode switching is all handled by these test routines.
F/B mode is active any time the 80 column switch is off and annunciator 3 is off. The other double hi-res RGB modes are activated by clocking two data bits and a "1" bit into a shift register on the AppleColor card. The value of the data bits determine which mode is activated. The data bits and the "1" bit are the setting of the 80 column switch at the time the shift register is clocked. The shift register is clocked by lowering the annunciator 3 switch.
ConvertLoResToFBHiRes first sets the main memory pixel buffer to a pattern of 24 black horizontal regions (0, "off") with 24 white bars (1, "on") interspaced. The "off" (excuse me, background) areas correspond to the even lo-res rows, and the "on" (foreground) to the odd rows. This works out to filling main $2XXX w/$00 and main $3XXX w/$7F. By using this pattern, I avoided having to manipulate the lo-res data before storing it in auxiliary memory. To understand this you must remember that even lo-res rows are stored in low nybbles and odd lo-res rows in high nybbles. After setting up main memory, the lo-res data is expanded 8:1 into the auxiliary memory color buffer. For example: $400 gets copied to aux $2000, $2400, $2800, $2C00, $3000, $3400, $3800, and $3C00. If this is viewed on a non-RGB monitor, all you'll see is 24 bars.
ConvertLoResToDoubleHiRes160 expands the lo-res data nybbles 16:1. Each lo-res byte is split into low and high nybbles. Each nybble is in turn duplicated in the other half of 8 bits and then copied into the main and auxiliary memory locations that correspond to the lo-res pixel the nybble used to be. For example: the low nybble of $400 gets copied to both nybbles of aux $2000, $2400, $2800, $2C00, and main $2000, $2400, $2800, $2C00; the high nybble of $400 gets copied to both nybbles of aux $3000, $3400, $3800, $3C00, and main $3000, $3400, $3800, $3C00. If you look at this on a monochrome monitor you'll see only 7/8ths of the data; it looks strange. Viewed on a non-RGB color screen, you'll get a mess of wrong colors.
The last routine, ConvertLoResToDoubleHiRes560, draws double hi-res monochrome patterns (NOT color patterns). I carefully studied the patterns lo-res makes when viewed on a monochrome monitor, writing down the constituent binary numbers. From that, I typed in the table "Monos", extending the patterns to include both even and odd offsets, and dividing them into auxiliary and main bytes. Once the table was defined, the routine just fell together ("automatically")! It uses each nybble and its Y-index LSB (NOT its Y-coord, but it works) to look up patterns from "Monos", and stores them into double hi-res memory.
If you would like to look at an attempt to convert lo-res to regular color double hi-res, you can change the monochrome routine to perform in color. First you should move the STA Column80On in "c" up four lines so that it is before the first STA AN3Off instead of the last one. This turns on mode 2 instead of mode 1. You will also need to include two more lines in subroutine ".2" of "ConvertLoResToDoubleHiRes560", and add a small table. I would put the table just before "Monos". Because the sample colors drawn by "Plot" (being 4 pixels wide) do convert correctly, be sure that there is a lot of text on the screen when you run the modified code. Change as follows:
.2 TAX
LDA Spin,X
ROL (.2 moved up from this line)
...rest of s/r...
Spin >hs 00.08.01.09.02.0A.03.0B
>hs 04.0C.05.0D.06.0E.07.0F
I've put the F/B hi-res mode to use many times to run programs like Asteroid Field (an oldie, but a goodie) and MousePaint on my RGB monitor. These programs were intended to be viewed on a monochrome monitor and, without help, they display unintended colors on RGB. By setting up F/B hi-res to display white on black (grey on brown looks good too) and then booting, I save having to turn on the monochrome NEC and turning my head to the left while playing (or painting). Here's how:
*C001:0 N C055:0 N C057:0 N 400:F0 N 401<400.4000M
C005:0 N 4000<2000.4000M C004:0 N
C054:0 N C000:0 N C05E:0 N 6^P
or *1/400:f0 n 1/401<1/400.6000m c05e 6^p (EDM ONLY)
These Monitor commands also write auxiliary text page 1. This is because there is a F/B 40-column text mode too!
1000 .LIST MOFF 1010 *SAVE dcj.Lo.to.HiRes 1020 LBas .eq $26,$27 1030 HBas .eq $2A,$2B 1040 ctr .eq $2E,$2F!!! 1050 Color .eq $30 1060 Store80Off .eq $C000 1070 Store80On .eq $C001 1080 Column80Off .eq $C00C 1090 Column80On .eq $C00D 1100 ReadColumn80 .eq $C01F 1110 MainPage .eq $C054 1120 AuxPage .eq $C055 1130 AN3Off .eq $C05E 1140 AN3On .eq $C05F 1150 *-------------------------------- 1160 a JSR Plot 1170 PHA save 40/80 state 1180 .1 JSR Pause2 1190 STA AN3Off (double (?) hi-res on) 1200 LDA $C057 hi-res (RGB F-B Hi-Res) 1210 JSR ConvertLoResToFBHiRes 1220 JSR Pause 1230 BNE .1 branch always 1240 *-------------------------------- 1250 b JSR Plot 1260 PHA save 40/80 state 1270 .1 JSR Pause2 1280 STA Column80On RGB MODE "4" 1290 STA AN3Off (160 Res 16 Color 1300 STA AN3On Double Hi-Res) 1310 STA Column80Off 1320 STA AN3Off 1330 STA AN3On 1340 STA Column80On 1350 STA AN3Off (double hi-res on) 1360 LDA $C057 hi-res 1370 JSR ConvertLoResToDoubleHiRes160 1380 JSR Pause 1390 BNE .1 branch always 1400 *-------------------------------- 1410 c JSR Plot 1420 sty $c07e //c... 1430 PHA save 40/80 state 1440 .1 JSR Pause2 1450 STA AN3Off RGB MODE 1 1460 STA AN3On (560 Res Monochrome 1470 STA AN3Off Double Hi-Res) 1480 STA AN3On 1490 STA Column80On 1500 STA AN3Off (double hi-res on) 1510 LDA $C057 hi-res 1520 JSR ConvertLoResToDoubleHiRes560 1530 JSR Pause 1540 BNE .1 branch always 1550 *-------------------------------- 1560 Pause2 LDA $C056 lo-res 1570 STA Column80Off 1580 STA AN3On (double hi-res off) 1590 LDA /$400 1600 STA LBas+1 1610 STA ctr page counter too 1620 Pause inc $400 lo-res active mark rqrd for "a" 1630 LDA $C000 wait for any key 1640 BPL Pause ...not yet 1650 STA $C010 clear strobe 1660 CMP #$8D clear Z-flag 1670 BNE .2 if NOT <return> 1680 PLA pop return address 1690 PLA 1700 STA AN3On (double hi-res off) 1710 LDA $C051 text 1720 PLA recover 40/80 state 1730 BMI .1 --->was 80-col 1740 STA Column80Off rqrd for "b" and "c" 1750 STA Store80off too 1760 RTS w/80 store off for 40-cols 1770 .1 STA Column80On / 1780 .2 RTS w/80 store and 80-cols on 1790 ConvertLoResToFBHiRes 1800 LDA /$2000 hi-res page 1 1810 STA HBas+1 1820 tya LDA #$00 even GR rows all 0 (background) 1830 JSR .3 1840 LDA #$7F odd GR rows all 1 (foreground) 1850 JSR .3 1860 .1 JSR RBSC picks lo-res too 1870 LDX #8 hi-res lines/lo-res row pairs ctr 1880 BIT AuxPage fill aux mem w/color nybbles 1890 .2 JSR NxtH store hi-res F-B pair/row pairs 1900 DEX 1910 BNE .2 1920 BIT MainPage 1930 INY 1940 BNE .1 1950 INC LBas+1 1960 DEC ctr 1970 BNE .1 loop for whole screen 1980 RTS 1990 .3 LDX #$10 page counter 2000 .4 STA (HBas),Y write main pixels 2010 INY 2020 BNE .4 2030 INC HBas+1 2040 DEX 2050 BNE .4 2060 RTS 2070 ConvertLoResToDoubleHiRes160 2080 .1 JSR RBSC picks lo-res too 2090 AND #$0F isolate even row nybble 2100 STA Color 2110 LSR line-up to left of msb 2120 JSR .2 2130 LDA (LBas),Y pick again 2140 AND #$F0 isolate odd row nybble 2150 STA Color 2160 JSR .2 2170 INY 2180 BNE .1 2190 INC LBas+1 2200 DEC ctr 2210 BNE .1 loop for whole screen 2220 RTS 2230 .2 ROR 2240 ROR 2250 ROR 2260 ROR 2270 ORA Color dup in other nybble 2280 LDX #4 hi-res lines/lo-res row ctr 2290 .3 BIT AuxPage 2300 STA (HBas),Y write aux $2XXX (or $3XXX) 2310 BIT MainPage 2320 JSR NxtH write main $2XXX (or $3XXX) too 2330 DEX 2340 BNE .3 2350 RTS 2360 * and for completeness: 2370 ConvertLoResToDoubleHiRes560 2380 .1 TYA 2390 ROR "column" lsb to carry 2400 PHP save for odd rows 2410 JSR RBSC picks lo-res too 2420 AND #$0F isolate even row nybble 2430 JSR .2 2440 LDA (LBas),Y pick again 2450 LSR isolate odd row nybble in LSN 2460 LSR 2470 LSR 2480 LSR 2490 PLP recover "column" lsb 2500 JSR .2 2510 INY 2520 BNE .1 2530 INC LBas+1 2540 DEC ctr 2550 BNE .1 loop for whole screen 2560 RTS 2570 .2 ROL double, merging "column" bit 2580 ASL double again for 4 bytes each 2590 TAX and shove it in an index reg 2600 LDA #4 hi-res lines/lo-res row ctr 2610 STA ctr+1 another counter loc... 2620 .3 BIT AuxPage 2630 LDA Monos,X 2640 STA (HBas),Y write aux $2XXX (or $3XXX) 2650 BIT MainPage 2660 LDA Monos+1,X 2670 JSR NxtH write main $2XXX (or $3XXX) too 2680 DEC ctr+1 should I have used Color? 2690 BNE .3 2700 RTS 2710 .ma hs ".gen (off)" macro 2720 .hs ]1 2730 .em 2740 Monos >hs 00.00.00.00 0--black 2750 >hs 11.22.44.08 1--magenta 2760 >hs 22.44.08.11 2--dark blue 2770 >hs 33.66.4C.19 3--purple 2780 >hs 44.08.11.22 4--dark green 2790 >hs 55.2A.55.2A 5--grey (1) 2800 >hs 66.4C.19.33 6--meduim blue 2810 >hs 77.6E.5D.3B 7--light blue 2820 >hs 08.11.22.44 8--brown 2830 >hs 19.33.66.4C 9--orange 2840 >hs 2A.55.2A.55 A--grey 2 (tan!) 2850 >hs 3B.77.6E.5D B--pink 2860 >hs 4C.19.33.66 C--light green 2870 >hs 5D.3B.77.6E D--yellow 2880 >hs 6E.5D.3B.77 E--aquamarine 2890 >hs 7F.7F.7F.7F F--white 2900 Plot LDA #$CC start @ top-right 2910 LDY #16 2920 .1 CLC 2930 LDX #3 2940 STA Color 00, 44, 88, CC 2950 .2 DEY 2960 STA $400,Y GR rows 0-3 2970 STA $480,Y 2980 ADC #$11 11, 55, 99, DD 2990 STA $500,Y GR rows 4-7 3000 STA $580,Y 3010 ADC #$11 22, 66, AA, EE 3020 STA $600,Y GR rows 8-11 3030 STA $680,Y 3040 ADC #$11 33, 77, BB, FF 3050 STA $700,Y GR rows 12-15 3060 STA $780,Y 3070 LDA Color 00, 44, 88, CC 3080 DEX 3090 BPL .2 3100 ADC #-$44 end, 00, 44, 88 3110 BCS .1 ...more 3120 com... STY HBas Y-reg zero! 3130 STY LBas 3140 LDA $C052 solid (40 x 48 pixels) 3150 STA Store80On page 1 (main) assumed 3160 LDA $C050 graphics 3170 LDA ReadColumn80 3180 RTS 3190 RBSC LDA LBas+1 Bob's trick 3200 EOR /$2000^$400 3210 STA HBas+1 3220 LDA (LBas),Y pick lo-res even-odd row pair 3230 RTS 3240 NxtH STA (HBas),Y store hi-res... 3250 INC HBas+1 new-old trick 3260 INC HBas+1 3270 INC HBas+1 3280 INC HBas+1 3290 RTS 3300 *-------------------------------- |
| Another Way Around the BRUN Problem | Anonymous Caller |
This morning I turned on my phone answering machine to play back the overnight messages. An anonymous caller calmly said, "This is an anonymous tip about the the BRUN problem under DOS. You can just BLOAD the program. Then CALL 41876, and the program will run properly and return nicely. You don't have to know the exact load address."
I checked it out, and it looks like our caller is correct. The BRUN processor inside DOS looks like this:
A38E- JSR BLOAD
A391- JSR IOHOOK
A394- JMP ($AA72)
By doing the complete BLOAD first, we have solved the problem of the trailing carriage return being printed after running our BRUNnable code. By the CALL 48176 (48176=$A394), we solve the problem of not knowing where the code loaded. In effect we have created a new BRUN command, which leaves out the call to IOHOOK and completes its own echoing before executing our code.
Thank you, Mr. Anonymous, whoever you are!
| PEA, PEI, PER Instructions in 65802/16 | Bob Sander-Cederlof |
These are three new instructions for pushing data on the stack which need more explanation than you find in the data sheet of these new chips. Furthermore, some mis-information has gotten out about them.
All three push two bytes of data on the stack. Furthermore, it makes no difference whether you are in Emulation or Native mode, except for a minor problem which I will mention later.
PEA (Push Effective Address) pushes the two bytes which follow the PEA opcode onto the stack. It is, in effect, a "push 16-bit-immediate-value" instruction. Here is an example, with the equivalent in old-fashioned 6502 code also shown:
0800- F4 34 12 PEA $1234
0800- A9 12 LDA /$1234
0802- 48 PHA
0803- A9 34 LDA #$1234
0805- 48 PHA
|
|
Notice that PEA takes 3 bytes and 5 cycles, while the equivalent 6502 code takes 6 bytes and 10 cycles.
If you were in native mode with the m-status-bit cleared (that is, with A-register in 16-bit mode), and forgot about the PEA opcode, you might do this:
0800- A9 34 12 LDA ##$1234
0803- 48 PHA
This approach takes 4 bytes and 7 cycles, and has the advantage or dis-advantage of leaving the data also in the A-register.
PEI (Push Effective Indirect) pushes two bytes from the direct page onto the stack. You might think of it as "push (dir)". The byte at dir+1 is pushed first, and then the byte at dir. Here is an example, with equivalent 6502 code:
Assume D=$0000, $0055 contains $34
$0056 contains $12
0800- D4 55 PEI $55
0800- A5 56 LDA $56
0802- 48 PHA
0803- A5 55 LDA $55
0805- 48 PHA
|
|
PEI takes 2 bytes and 6 cycles, and the equivalent 6502 code takes 6 bytes and 12 cycles. In Native 16-bit mode, you could use LDA $55 to pick up both bytes, and a single PHA to push both of them. This would take 3 bytes and 8 cycles. PER (Push Effective Relative) is very similar to the PEA instruction. By analogy, PER is to PEA as BRL is to JMP. The processor adds the value in the two bytes following the opcode to the contents of the PC-register, and pushes the result (high-byte first) onto the stack. Before the addition takes place, the PC-register will have already been advanced to the first byte of the next instruction. Here is an example:
0800- 62 52 A2 PER $AA55
0803-
| 
|
The value of PC after reading the PER instruction will be $0803. Adding $0803 to $A252 gives $AA55.
There is an idiosyncrasy (bug?) in the 65802 and I presume in the 65816 in the emulation mode, having to do with instructions which push two bytes on the stack. The three instructions discussed here (PEA, PEI, and PER), as well as the PHD instruction, all exhibit this problem. If the stack pointer is at $00 (remember, in emulation mode the stack pointer is only 8-bits wide and always points into page 1), you would expect the two bytes to be stored at $0100 and $01FF. However, the processor stores the "high" byte at $0100 as it should, and then stores the "low" byte at $00FF instead of $01FF. The following code will prove it to you, if you have the chip in your computer:
LDX #$00
STX $FF
STX $1FF
TXS
PEA $1234
LDA $FF
JSR $FDDA
LDA $100
JSR $FDDA
LDA $1FF
JSR $FDDA
JMP $3D0
|
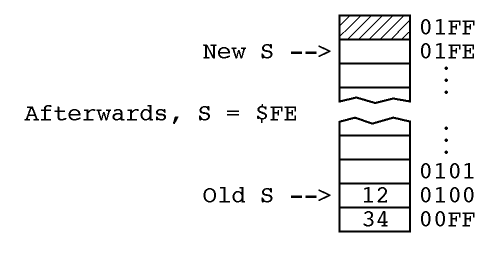
|
The program above will print out "341200". This means that the PEA instruction pushed the value $34 into $00FF, rather than $01FF. If you plan to use these instructions in emulation mode, be sure you are aware of this un-expected case.
Apple Assembly Line is published monthly by S-C SOFTWARE CORPORATION, P.O. Box 280300, Dallas, Texas 75228. Phone (214) 324-2050. Subscription rate is $18 per year in the USA, sent Bulk Mail; add $3 for First Class postage in USA, Canada, and Mexico; add $14 postage for other countries. Back issues are available for $1.80 each (other countries add $1 per back issue for postage).
All material herein is copyrighted by S-C SOFTWARE CORPORATION,
all rights reserved. (Apple is a registered trademark of Apple Computer, Inc.)
![]()